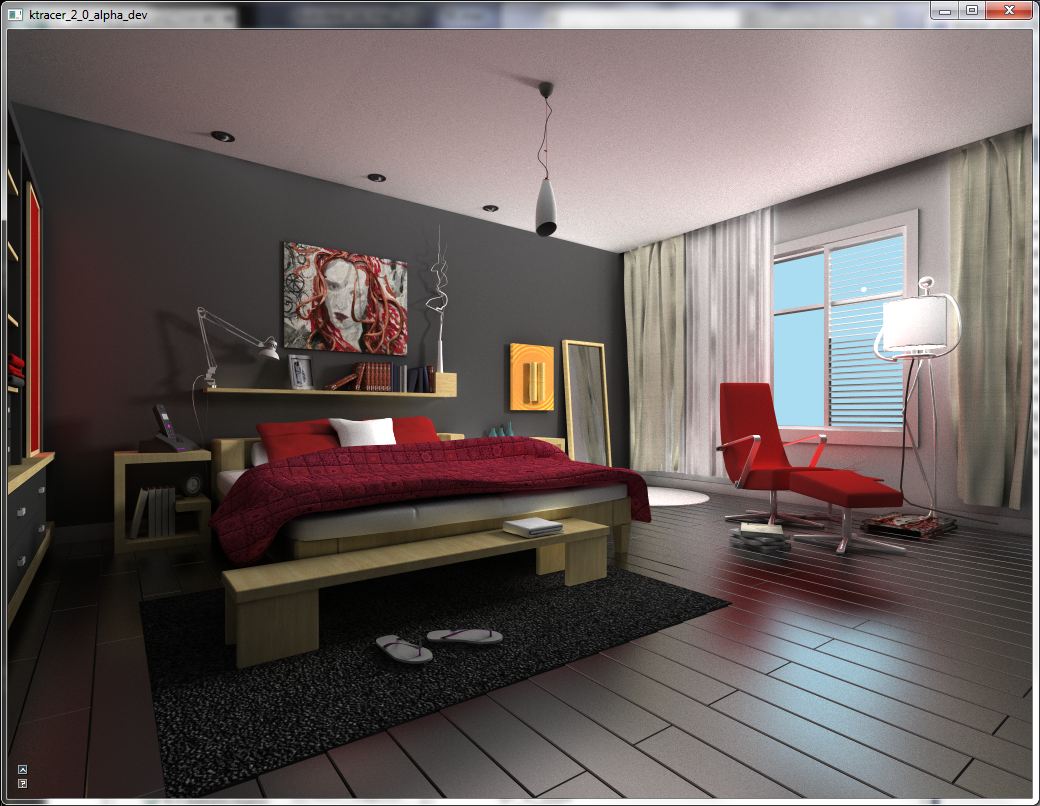
First, I found a pretty serious bug with the photon shooting/scattering part of the tracer. For all the photons, only the first-bounce photons were recorded with correct power; the later, multi-bounce photons had zero power. Essentially, the renderer was only rendering first bounce indirect lighting, and that explains why the Sponza scene was so dark. I only discovered this problem when I started to directly visualize all the photons on the screen (which I should've done a lot earlier...) Anyways, this is the current rendered image of the Sponza scene. Note that the color bleeding is much more interesting, and I also added sky color bleeding, which is added to the image whenever secondary rays hit the sky, and sun-like parallel lighting,

Inspired by the idea of irradiance caching, we apply a final post-processing step so that we can minimize the number of required final gather samples per pixel while achieving similar results. The basic idea is to do an image-space irradiance interpolation on the rendering canvas. For each one of the pixels, x, in the canvas in parallel, we examine all the surrounding pixels within a preset radius r. For each of the nearby pixel xj, we compute its weight by

where x, xj, n(x), n(xj) are the spatial positions for the two pixels and their respective normals. The rj term is a harmonic means of the distances from the xj to nearby geometry. This value can be easily while final gathering is done on each pixel, where we have the distance information for each final gather sample, via the following formula:

Where N is the number of final gather samples, di is the distance to each secondary intersection. Note that in order to progressively compute the value of rj, we compute its reciprocal, 1/rj, so that for each additional final gather sample, we can simply add 1/di/N to the current 1/rj value.
With all the weights computed, we can compute the diffuse irradiance value at x by

The three images below showcases the effects of the post-processing step. The top image is rendered with only 12 samples/pixel, without the postprocessing step. The middle image is postprocessed, with the same 12spp setting, rendered in 2.2 seconds. The bottom image is a reference image rendered with 300spp, taking 42.3 seconds to render. All three images are rendered with 800x800 resolution and 200,000 photons. Notice the smoothness in indirect lighting in the middle image, but also note its problem: the places where Rx is small (local geometry hinders the light reception) lost the darkness. This problem might be addressed by shooting more final gather rays and avoid interpolation for those spots and is worth future research.



Finally a video showing the current status of the renderer:












{kind=link}
{kind=link}